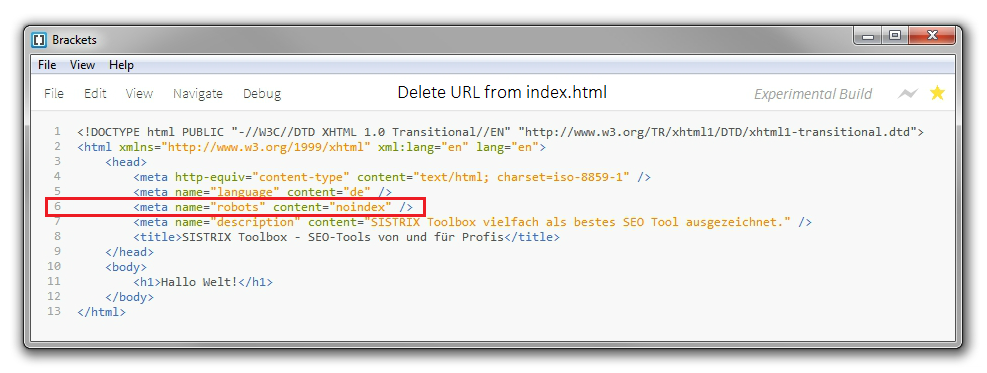
To use the advisor we need to query the V$INSTANCE_RECOVERY VIEW.
If our redo log file size is under sized then the checkpoint process is driven by WRITES_LOGFILE_SIZE i.e. its driven by the smallest redo log file size.
This can be clarified by quering the V$INSTANCE_RECOVERY VIEW.
Lets say one of our Log file is too small and we have set the FAST_START_MTTR_TARGET=30
We have done some Transactions which has generated redo entries , now we would like to capture the minimum optimal size of the redo log file.
SELECT TARGET_MTTR,ESTIMATED_MTTR,WRITES_MTTR,WRITES_LOGFILE_SIZE,
OPTIMAL_LOGFILE_SIZE FROM V$INSTANCE_RECOVERY;
TARGET_MTTR ESTIMATED_MTTR WRITES_MTTR WRITES_LOGFILE_SIZE OPTIMAL_LOGFILE_SIZE
----------- -------------- ----------- -------------------------------------
30 28 0 102232
Its clear from the above query that the chekpoint is driven by WRITES_LOGFILE_SIZE as described above and the advice is to have a Log file size of atleast 32MB Size.
Now if we recreate the log file with the size recommendation ie 32 MB and fire the same query again lets see what happens
SELECT TARGET_MTTR,ESTIMATED_MTTR,WRITES_MTTR,WRITES_LOGFILE_SIZE, OPTIMAL_LOGFILE_SIZE FROM V$INSTANCE_RECOVERY;
TARGET_MTTR ESTIMATED_MTTR WRITES_MTTR WRITES_LOGFILE_SIZE
OPTIMAL_LOGFILE_SIZE
----------- -------------- ----------- -------------------
--------------------
34 38 924 0
32
This shows that the checkpoint is now driven by WRITES_MTTR ie the FAST_START_MTTR parameter.
CAVEAT: An online redo log file’s size is considered optimal if it does not drive incremental checkpointing more aggressively than needed by FAST_START_MTTR_TARGET.